马哈鱼数据血缘分析器(产品英文名为 Gudu SQLFlow )是一款业内领先的数据血缘分析工具,拥有众多国内外大企业客户。
导航


帮你解决数据治理中常见的问题
易用且强大的血缘分析工具
支持超过20多种主流数据库
上百个专业数据治理团队使用
每年上万个用户的选择
累计处理上千万条 SQL 语句
他们都在使用马哈鱼,用户的认可始终为我们注入支持与力量









马哈鱼数据血缘分析器是一个分析数据血缘关系的平台,可以在线直接递交 SQL 语句进行分析,也可以选择连接指定数据库获取 metadata、从本地上传文件目录、或从指定 git 仓库获取脚本进行分析。
本文介绍如果利用马哈鱼来分析SQL的case-when语句中字段依赖关系。
考虑如下SQL:
select case when a.kamut=1 and b.teur IS null then 'no locks' when a.kamut=1 then b.teur else 'locks' end teur from tbl a left join TT b on (a.key=b.key)
SQL的返回字段 teur,它的值直接于case-when的计算结果。
在马哈鱼的设计理念里,case-when被认为是一种特殊的function,但又不同于普通的function,它并没有argument。马哈鱼直接分析case when中的when、then、else子句。
其中,then、else子句的字段直接作为返回结果提供给teur,因此毫无疑问,then、else子句的字段和teur是一个fdd关系。需要考虑的是when子句,teur的结果是间接依赖when子句,满足不同的when子句,会返回不同的then结果,这会影响到最终teur字段的返回值。因此:
when --> fdr --> then --> fdd --> resultset column
此处的when子句非常类似where语句,只不过影响的是then子句,而不是直接影响resultset column。
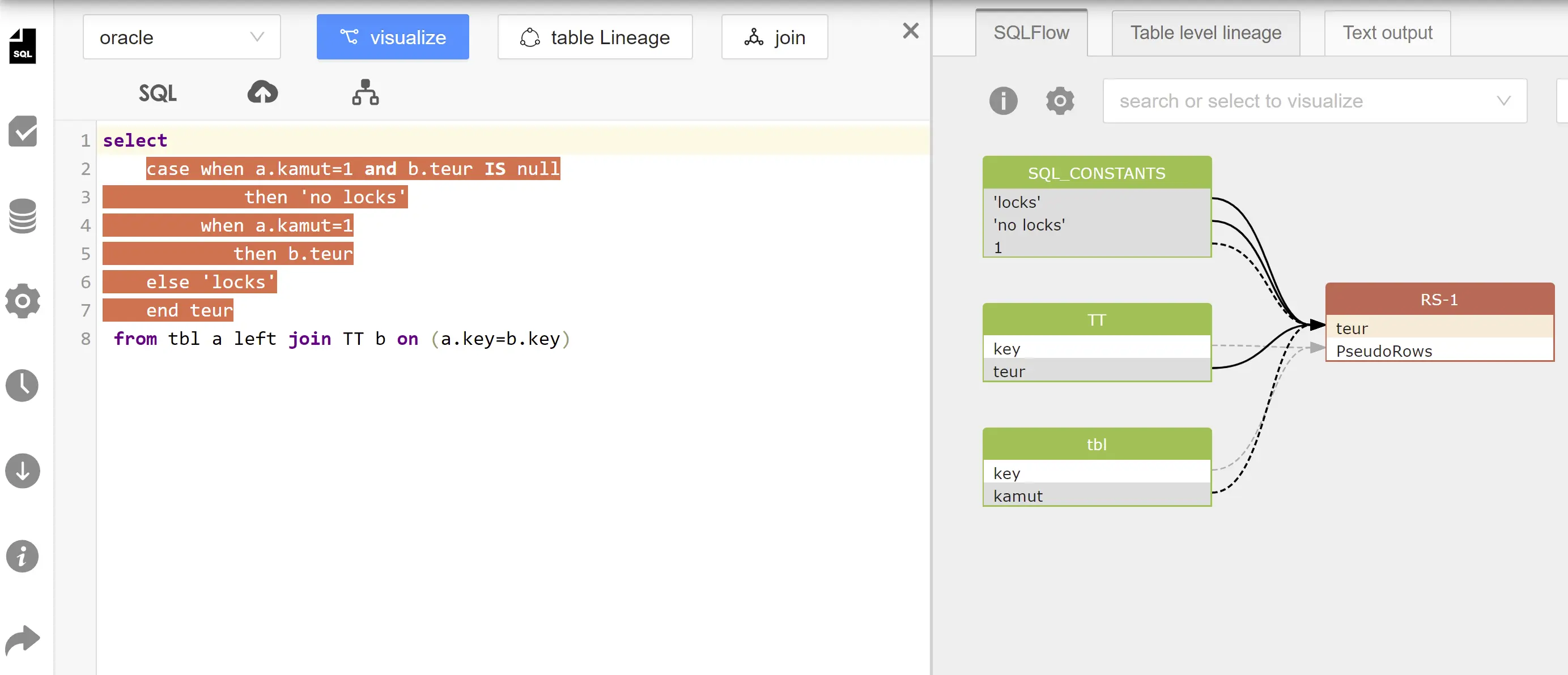
如图所示:
teur和两个when子句:a.kamut=1 and b.teur IS null, a.kamut=1,产生了fdr关系,因此
a.kamut --> fdr -->teur, 1 --> fdr --> teur, b.teur --> fdr --> teur
teur和2个then子句及else子句产生了fdd关系,因此
'no locks' --> fdd --> teur, b.teur --> fdd --> teur, 'locks' --> fdd --> teur
其中b.teur和teur直接同时存在了fdd和fdr关系,由于fdd关系优先级高于fdr关系,因此在graph中,只显示出了fdd关系。
CREATE VIEW FACT_PRCU_FLDR AS
SELECT
PRCU.PRCU_ID AS PRCU_FLDR_ID,
CONCAT(PRCU.PRCU_TYP_ID,'^','^') AS PRCU_FLDR_TYP_ID,
CONCAT('^',PRCU.BUYR_ID) AS BUYR_STAFF_ID,
CONCAT('^',PRCU.MGR_ID) AS MGR_STAFF_ID,
CONCAT(PRCU.BUYR_TEAM,'^') AS BUYR_TEAM_STAFF_ID,
PRCU.CMPLX_CD AS PRCU_CMPLX_ID,
PRCU.RNG_CD AS PRCU_RNG_ID,
(CASE WHEN PRCU.NO_ST IS NOT NULL AND PRCU.NO_ST_COMPLETE IS NOT NULL
THEN (PRCU.NO_ST - PRCU.NO_ST_COMPLETE)
END) AS NO_ORD_ST,
(CASE WHEN PRCU.COMPLETE_FL=1 THEN 'Final'
WHEN (CASE WHEN PRCU.NO_ST IS NOT NULL AND PRCU.NO_ST_COMPLETE IS NOT NULL
THEN (PRCU.NO_ST - PRCU.NO_ST_COMPLETE)
END) > 0 THEN 'Alert!'
ELSE 'Ok'
END) AS FLDR_COMPLETE,
PRCU.PRCU_ID,
PRCU.PRCU_TYP_ID,
PRCU.PRCU_DSCR,
PRCU.EXPT_COMPLETE_DT,
PRCU.CLSD_DT,
PRCU.BUYR_ID,
PRCU.MGR_ID,
PRCU.BUYR_TEAM,
PRCU.CMPLX_CD,
PRCU.RNG_CD,
PRCU.COMPLETE_FL,
COALESCE(PRCU.NO_ST,0) AS NO_ST,
COALESCE(PRCU.NO_ST_COMPLETE, 0) AS NO_ST_COMPLETE,
CVLST.CVL_PRCU_ST_ID_DV AS "LAST_ST_COMPLETE",
COALESCE(PRCU.TOT_AMT, 0) AS TOT_AMT,
PRCU.TBL_LAST_DT,
PRCU.PRCU_TITLE,
(SELECT MIN(CREA_DT) FROM R_PRCU_ST ST WHERE PRCU.PRCU_ID=ST.PRCU_ID AND ST.CREA_DT IS NOT NULL) FLDR_CREA_DT,
COALESCE(PRCU.ORGNL_PRCU_TOT_AM, 0) AS ORGNL_PRCU_TOT_AM,
CONCAT(PRCU.EXT_STOR_UNID,'^R_PRCU_ID')AS EXT_ID,
/*INSIGHT_LITE_COLUMNS_STRT*/
0 AS REC_ST,
PRCU.TBL_LAST_DT AS LAST_PROCESS_DT
/*INSIGHT_LITE_COLUMNS_END*/
/*INSIGHT_COLUMNS_STRTPRCU.REC_ST,PRCU.LAST_PROCESS_DTINSIGHT_COLUMNS_END*/
FROM
R_PRCU_ID PRCU LEFT OUTER JOIN CVL_PRCU_ST_ID CVLST ON
PRCU.LAST_ST_COMPLETE = CVLST.CVL_PRCU_ST_ID_SV
查看其中的case-when语句
(CASE WHEN PRCU.COMPLETE_FL=1 THEN 'Final' WHEN (CASE WHEN PRCU.NO_ST IS NOT NULL AND PRCU.NO_ST_COMPLETE IS NOT NULL THEN (PRCU.NO_ST - PRCU.NO_ST_COMPLETE) END) > 0 THEN 'Alert!' ELSE 'Ok' END) AS FLDR_COMPLETE
可以看到ResultSet Column FLDR_COMPLETE 被一个case-when语句影响,而其中的第二个When子句又包含了一个case-when语句。
当case-when语句整体作为when子句时,这个子句的fdd关系,实际上是外层when子句fdr关系的一部分,即:
then -->fdd-->when-->fdr-->FLDR_COMPLETE
因此内层case-when的then子句和resultset column FLDR_COMPLETE的关系是fdr关系,而不是fdd关系。
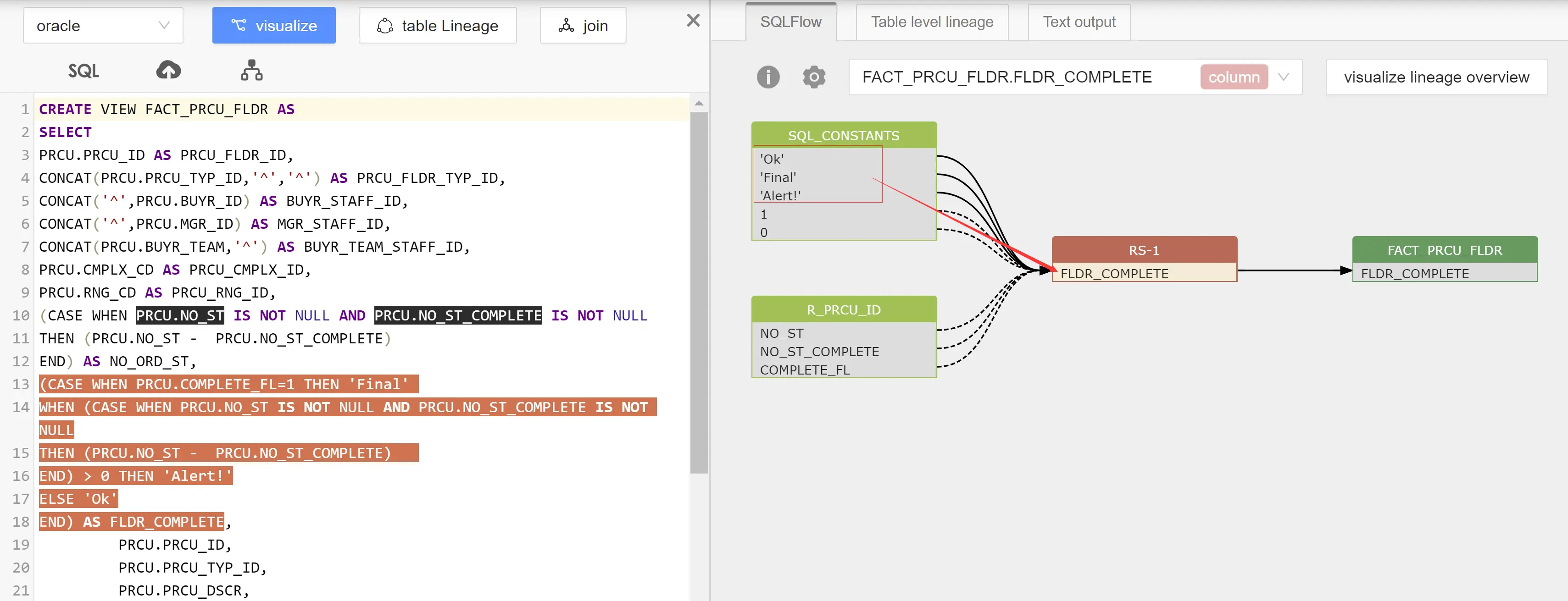
如图所示,最终影响FLDR_COMPLETE的fdd字段,仅有外层case-when的then语句和else语句,其他的都显示为fdr关系。
以上就是对马哈鱼分析case-when语句的处理流程介绍,关于马哈鱼的等多功能,请参考下面链接:
马哈鱼数据血缘关系分析工具中文网站: https://www.sqlflow.cn
马哈鱼数据血缘关系分析工具在线使用: https://sqlflow.gudusoft.com








